We consider the Robbins-Monro update
 + \epsilon_n]")
and argue that this can be approximated by the o.d.e.:
).")
The condition for convergence used was

Put informally, the condition 

Given that noise is suppressed and increments get small, it is natural to ask how close the above process is to the ordinary differential equation
Moreover, can Lyapunov stability results [that we applied earlier] be directly applied to prove the the convergence of the corresponding stochastic approximation scheme? Often, the answer is yes. And this has certain conceptual advantages, since the Lyapunov conditions described earlier can be quite straightforward to establish and also we don’t need to directly deal with the compounding of small stochastic errors from the sequence 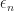
The set up. The idea is to let

Here 
 = x_n , \qquad \text{for } t = t_n")
We let 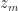
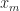

),\quad \text{and}\quad z_m(t_m) = x_m.")
We then compare 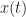

 - z_m(t) ||\, .")
Assumptions. In addition to the Robbins-Monro condition , we make the following assumptions.
is Lipschitz continuous.
- For
 and
and .
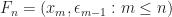
Main result. A key result that we will prove is the following proposition
Proposition 1.
 - z_m(t) || = 0\, .")
where convergence holds with probability 
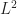
Proof. Notice
 = x_m + \int_{t_m}^{t_n} z_m(u) du")
while
 = x_m + \sum_{k=m}^{n-1} \alpha_k g(x_k) + \sum_{k=m}^{n-1} \alpha_k \epsilon_k = x_m + \int_{t_m}^{t_n} g( x ( \lfloor u \rfloor_\alpha )) du + \sum_{k=m}^{n-1} \alpha_k \epsilon_k\end{aligned}")
where 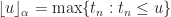
 - x(t_n) || & \leq \Big|\Big| \sum_{k=m}^{n-1} \alpha_k \epsilon_k \Big| \Big| + \int_{t_m}^{t_n} || g( z_m (u)) - g( x ( \lfloor u \rfloor_\alpha )) || du \\ & \leq \Big|\Big| \sum_{k=m}^{n-1} \alpha_k \epsilon_k \Big| \Big| + \int_{t_m}^{t_n} || z_m ( u )- x ( \lfloor u \rfloor_\alpha )|| du \end{aligned}")
which implies by Gronwall’s Lemma  - x(t_n) || \leq \Big|\Big| \sum_{k=m}^{n-1} \alpha_k \epsilon_k \Big| \Big| e^{L(t_n-t_m)} \leq \big|\big| M_n-M_m\big| \big| e^{LT} \, .")
where the final inequality holds for 
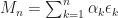

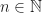

where ![K =\max_k \mathbb E [ \epsilon_k^2]](https://s0.wp.com/latex.php?latex=K+%3D%5Cmax_k+%5Cmathbb+E+%5B+%5Cepsilon_k%5E2%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
 with probability
with probability
 - x(t) || = 0\, .")
QED.
Applying the o.d.e limit.
Before we focus on the proof of Proposition 1 it’s worth explaining how it can be applied. The main idea is to
- Check that the o.d.e. convergence by showing gets close to the some desired set of points
in
time units for each initial condition
,
.
- Then apply Proposition 1 to show that the stochastic approximation is also close to the o.d.e at time
This is sufficient to show that the stochastic approximation converges to
Here, we combine La Salle’s Invariance Principle, Theorem 2, with Proposition 1, though, in principle, we could have considered any of the ode results from Lyapunov Functions. We assume that the assumptions of Proposition 1 are satisfied. In addition we assume,
- Almost surely,

Further we recall that for La Salle’s Invariance Principle, we assumed there was a Lyapunov function 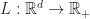
is continuously differentiable .
for all
.
- The sets
are compact for all
.
Also we defined 
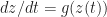



Theorem 1. For the stochastic approximation scheme
 + \epsilon_n ]")
described in Proposition 1 and given a Lyapunov function

Proof. First we check that the o.d.e solutions 

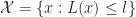
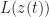

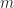

Next we set up the bounds from the two results. From La Salle’s Invariance Principle, we know that 



 - x^\star | \leq \epsilon \, .")
Taking this choice of 

 - z_m(t) || \leq \epsilon.")
Notice we can take 

\, .")
Now notice that if 
![t_n \in [t_m+T,t_m+2T]](https://s0.wp.com/latex.php?latex=t_n+%5Cin+%5Bt_m%2BT%2Ct_m%2B2T%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

 || + \min_{x^\star} || z_m(t_n) - x^\star || \leq 2\epsilon\,.")
Thus we see, with the union above, that for all 
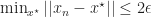

References
The o.d.e approach to stochastic approximation was initiated by Ljung. Shortly after it is was extensively developed by Kushner, see below for two text book accounts. The arguments above loosely follow the excellent text of Borkar. We shorten the proof in several ways and consider
.Benveniste, M. Metivier, and P. Priouret. Adaptive algorithms and stochastic approxima- tions, volume 22. Springer Science & Business Media, 2012.
V. S. Borkar. Stochastic approximation: a dynamical systems viewpoint, volume 48. Springer, 2009.
H. Kushner and G. G. Yin. Stochastic approximation and recursive algorithms and applications, volume 35. Springer Science & Business Media, 2003.
H. J. Kushner and D. S. Clark. Stochastic approximation methods for constrained and un- constrained systems, volume 26. Springer Science & Business Media, 1978.
Ljung. Analysis of recursive stochastic algorithms. IEEE Transactions on Automatic Control, 22(4):551-575, 1977.


