We want to optimize the expected value of some random function. This is the problem we solved with Stochastic Gradient Descent. However, we assume that we no longer have access to unbiased estimate of the gradient. We only can obtain estimates of the function itself. In this case we can apply the Kiefer-Wolfowitz procedure.
The idea here is to replace the random gradient estimate used in stochastic gradient descent with a finite difference. If the increments used for these finite differences are sufficiently small, then over time convergence can be achieved. The approximation error for the finite difference has some impact on the rate of convergence.
The Problem Setting
Suppose that we have some function
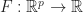
 = \mathbb E_U [ f (\theta ; U) ],")
that we wish to minimize over 
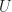
We suppose that we do not have direct access to the distribution of 



We can think of 
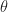
The Kiefer-Wolfowitz Algorithm
If the problem is reasonably smooth then we can use the Keifer-Wolfowitz proceedure to optimize 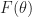

A finite difference approximation. We want to approximate the gradient of 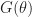
 := \nabla F(\theta) \, .")
We define for

 := (F( \theta + \gamma \bm e_i ) : i =1,...,p)")
where 

 := \frac{F(\bm \theta + \bm \gamma ) - F(\bm \theta - \bm \gamma ) }{2\gamma}")
It is not hard to show that for a well-behaved function 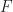
 + G_{\gamma}(\bm\theta) = O( \gamma^2) \, .")
(Also note that higher-order bounds can also be used here for an improved rate of convergence.)
The Algorithm
The Kiefer-Wolfowitz Algorithm performs the update
-f(\bm\theta_t-\bm\gamma_t,U_t)}{2\gamma_t}
\right]")
I.e. we replace the finite difference estimate of 

We need to choose 

Assumptions
We make the following assumptions on 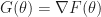
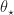

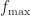
^\top ( \bm\theta- \bm\theta_\star) \geq 0 , && \forall \bm\theta \label{KW:As1} \\
&
\big( G(\bm\theta) - G(\bm\phi) \big)(\bm\theta -\bm\phi) \geq \kappa \left\|
\bm\theta-\bm\phi
\right\|^2 , && \forall \bm\theta \, \label{KW:As2}
\\
&
\left\|
G(\bm\theta) - G_{\gamma} (\bm\theta)
\right\|
\leq c\gamma^2 && \forall \bm\theta \label{KW:As3}
\\
& |f(\bm\theta, U)| \leq f_{\max} , && \forall \bm \theta, \forall U\, .\end{aligned}") Notice that if
Notice that if
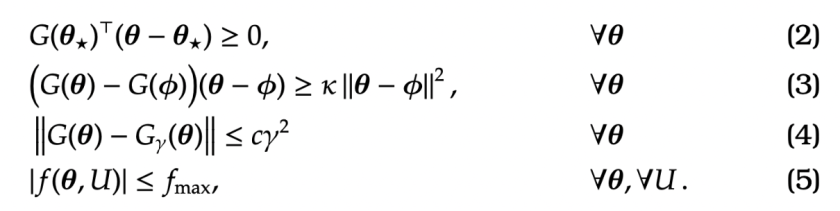
We also place assumptions on the sequences 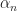

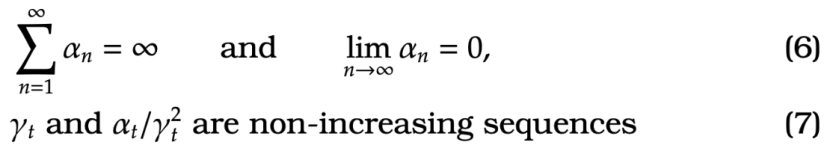

Main Result
THEOREM. For the Kiefer-Wolfowitz procedure , if (2-7) hold then

Specifically if we take 
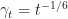

 The proof of Theorem relies on the following proposition.
The proof of Theorem relies on the following proposition.
PROPOSITION. Given 


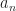
 if
if
 + a_n b_n \xi^{1/2}_n + e_n a_n\, ,")
then

We prove this Proposition at the end of this section. Notice that we proved similar bounds to the above for Robbins-Monro.
Proof of Theorem. We can rewrite the Kiefer-Wolfowitz recursion as

+
\alpha_t \bm\beta_t
+
\alpha_t \epsilon_t")
where  - G_{\gamma_t}(\bm\theta_t)
\quad
\text{and}
\quad
\epsilon_t
=
G_{\gamma_t} (\bm\theta_t)
-
\left[
\frac{
f(\bm\theta_t + \gamma_t , U_t)
-
f(\bm\theta_t - \gamma_t , U_t)}{2 \gamma_t}
\right] \,.") Setting
Setting

notice that ^\top \Big( \bm\theta_t - \bm\theta_\star \Big)
\right]
+
\mathbb E \left[
\left\|
\bm\theta_{t+1} - \bm\theta_t
\right\|^2
\right]
\notag
\\
=\,
&
\;\; z_t \notag
\\&+
2\mathbb E \left[
-\alpha_t G(\bm\theta_t)^\top (\bm\theta_t -\bm\theta_\star)
\right] \label{KW:e1}
\\&
+
2 \mathbb E \left[
\alpha_t \bm\beta_t (\bm\theta_t -\bm\theta_\star)
\right]
\label{KW:e2}
\\&
+
2 \mathbb E \left[
\alpha_t \epsilon_t ( \bm\theta_t - \bm\theta_\star)
\right]\label{KW:e3}
\\&+ \mathbb E \left[
\left\|
\bm\theta_{t+1} - \bm\theta_t
\right\|^2
\right]\label{KW:e4}\end{aligned}")
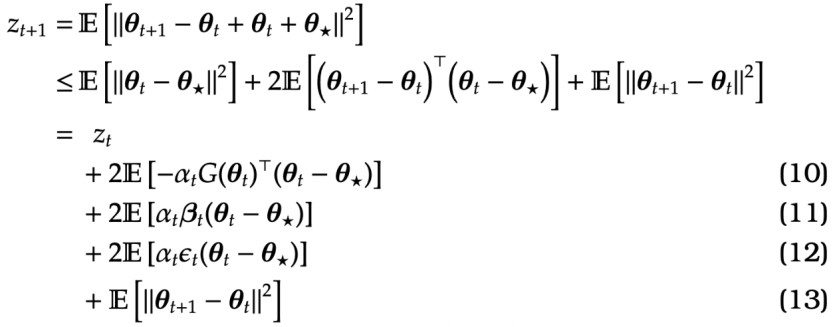
We now bound the four terms above.
We can bound (10) as follows
^\top (\bm\theta_t-\bm\theta_\star)
\right]
\notag
\\
\leq \,
&
-2\alpha_t \mathbb E \left[
(G(\bm\theta_t) - G(\bm\theta_\star) )
(\bm\theta_t - \bm\theta_\star)
\right]
\tag{By Assumption \eqref{KW:As1}}
\\
\leq \,
&
-2\alpha_t \kappa \mathbb E\left[
\left\|
\bm\theta_t -\bm\theta_\star
\right\|
\right]
\tag{By Assumption \eqref{KW:As2}}
\\
=\,
&
-2 \kappa \alpha_t z_t \label{KW:eq1}\end{aligned}")
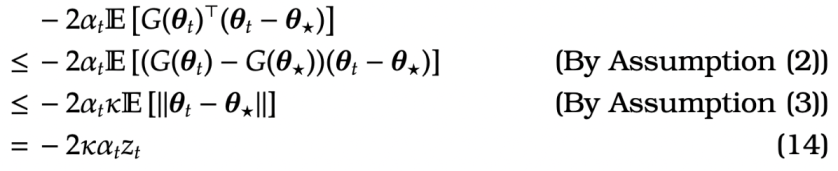
For the term (11), by Cauchey-Schwartz
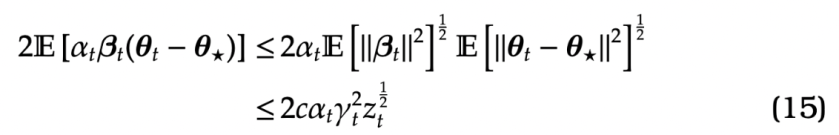
In the final inequality above we note that from Assumption (4) that:  - G_{\gamma_t} (\bm\theta_t)
\right\|
\leq c\gamma_t^2 \label{KW:eq3}
%\end{aligned}")

For term (12), we have ] = 0
%\end{aligned}")

because ![\mathbb E[ \epsilon_t | \theta_{t} ]=0](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5B+%5Cepsilon_t+%7C+%5Ctheta_%7Bt%7D+%5D%3D0&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
For term (13)

Applying (14), (15), (16) and (17) to (10), (11) , (12) and (13) gives 

By the proposition above with 




From this we see that the required result holds.
For 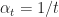


which gives the final required expression. QED.
We now prove Proposition. We do so by proving Lemmas 1 and 2.
LEMMA 1. If
 + \alpha_n B")
and

then

PROOF. Rearranging gives
.")
If 

\leq -\alpha_n ( A [B/A + \epsilon] -B)
= -\alpha_n A \epsilon\, .")
So 


Notice, 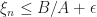

Thus, we see that

Therefore

Since 
LEMMA 2. If
 + \alpha_n \beta_n B")
and
")
with 

PROOF. Since 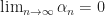
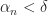

Now defining 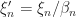
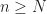
 \xi_n'
+
\alpha_n \frac{\beta_n}{\beta_{n+1}} B
\notag
\\
\leq \,
&
\left(
1+C\alpha_n
\right)
\left(
1-A\alpha_n
\right)\xi'_n + \alpha_n \left(
1+C\alpha_n
\right)B\notag
\\
\leq \,
&
\left(
1 -(A-C +\delta) \alpha_n
\right)\xi'_n + \alpha_n (1+C \delta) B
\notag
\\
=\,
&
(1-A'\alpha_n) \xi'_n + \alpha_n B'\end{aligned}")
where we define 
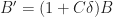

which recalling the definitions of 
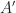

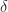
Proof of Proposition. By the inequality

we have
 + a_n b^2_n + e_n a_n\, .")
Now the results follow by applying Lemma 2. With 

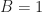

References
The Kiefer-Wolfowitz procedure was first proposed by Kiefer and Wolfowitz (1952). Finite time bound similar to those in the Theorem above are given by Broadie et al. (2011). The analysis here largely follows from the arguments in Fabian (1967). Fabian and Broadie et al. both use results from Chung (1954), which is the basis for Lemmas 1 and 2 above.
Kiefer, J., & Wolfowitz, J. (1952). Stochastic estimation of the maximum of a regression function. The Annals of Mathematical Statistics, 462-466.
Broadie, M., Cicek, D., & Zeevi, A. (2011). General bounds and finite-time improvement for the Kiefer-Wolfowitz stochastic approximation algorithm. Operations Research, 59(5), 1211-1224.
Fabian, V. (1967). Stochastic approximation of minima with improved asymptotic speed. The Annals of Mathematical Statistics, 191-200.
Chung, K. L. (1954). On a stochastic approximation method. The Annals of Mathematical Statistics, 463-483.
