Kalman filtering (and filtering in general) considers the following setting: we have a sequence of states 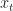
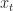
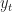

Consider the equations

where 

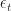
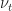


The Kalman filter has two update stages: a prediction update and a measurement update. These are
 and
and
where
\, .\end{aligned}")
The matrix 
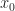

We will use the following proposition, which is a standard result on normally distributed random vectors, variances and covariances,
Prop 1. Let 
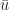

\, .")
i) For any matrix 

\, .")
ii) If we take 
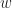

 \sim \mathcal N (\bar{\bm w} + \Sigma_{w v} \Sigma^{-1}_{v v} (\bm v - \bar{\bm v}) ,\Sigma_{ww} - \Sigma_{w v} \Sigma^{-1}_{v v} \Sigma_{v w} )")
iii) 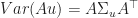

We can justify the Kalman filtering steps by proving that the conditional distribution of 
Theorem 1.
 & \sim \mathcal N ( \hat{\bm x}_{t+1|t } , P_{t+1|t} ) \\ (\bm x_{t+1} | \bm y_{[0:t+1]}, \bm a_{[0:t]} ) & \sim \mathcal N ( \hat{\bm x}_{t+1|t+1 } , P_{t+1|t+1} )\end{aligned}")
where ![y_{[0:t]} := (y_0,...,y_{t})](https://s0.wp.com/latex.php?latex=y_%7B%5B0%3At%5D%7D+%3A%3D+%28y_0%2C...%2Cy_%7Bt%7D%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![a_{[0:t]} := (a_0,...,a_{t})](https://s0.wp.com/latex.php?latex=a_%7B%5B0%3At%5D%7D+%3A%3D+%28a_0%2C...%2Ca_%7Bt%7D%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Proof. We show the result by induction supposing that
 \sim \mathcal N ( \hat{\bm x}_{t|t } , P_{t|t} )\, .")
Since
 \sim \mathcal N ( \hat{\bm x}_{t+1|t } , P_{t+1|t} )\, .")
where, by Prop 1ii), we have that

Given 
![Var(y_{t+1} | y_{[0,t]}, a_{[0,t]}) = C_t P_{t+1|t} C^\top_t](https://s0.wp.com/latex.php?latex=Var%28y_%7Bt%2B1%7D+%7C+y_%7B%5B0%2Ct%5D%7D%2C+a_%7B%5B0%2Ct%5D%7D%29+%3D+C_t+P_%7Bt%2B1%7Ct%7D+C%5E%5Ctop_t+&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![Cov(x_{t+1}, y_{t+1} | y_{[0,t]}, a_{[0,t]}) = P_{t+1|t} C^\top_t](https://s0.wp.com/latex.php?latex=Cov%28x_%7Bt%2B1%7D%2C+y_%7Bt%2B1%7D+%7C+y_%7B%5B0%2Ct%5D%7D%2C+a_%7B%5B0%2Ct%5D%7D%29+%3D+P_%7Bt%2B1%7Ct%7D+C%5E%5Ctop_t+&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
 \sim \mathcal N \left( [ \hat{\bm x}_{t+1|t } , C_t \hat{\bm x}_{t+1|t } ] , \left[ \begin{array}{ll} P_{t+1|t} & P_{t+1} C^\top_t \\ C_t P_{t+1|t} & C_t P_{t+1} C_t^\top + \Sigma^\eta_t \end{array} \right) \right]\, .\end{aligned}")
Thus applying Prop 1ii), we get that
 & = ( (x_{t+1} | y_{[0:t]} , a_{[0:t]} ) | y_{t+1}) \\ & \sim \mathcal N \Big( \hat{\bm x}_{t+1|t} + P_{t+1 | t} C^\top_t [ C_t P_{t+1} C^\top_t + \Sigma^\eta_t ]^{-1} ( y_{t+1} - C_t \hat{\bm x}_{t+1|t} ) \, ,\\ & \qquad\qquad \qquad\quad P_{t+1|t} - P_{t+1|t} C^\top_t [ C_t P_{t+1|t} C_t^\top + \Sigma^\eta_t ]^{-1} C_t P_{t+1|t} \Big)\, . \end{aligned}")
$ \square$
Literature
The Kalman filter is generally credited to Kalman and Bucy. The method is now standard in many text books on control and machine learning.
Kalman, Rudolph E., and Richard S. Bucy. “New results in linear filtering and prediction theory.” (1961): 95-108.
