We consider a network of wireless routers. The routers that are close together can interfere if they transmit simultaneously. So schedules need to avoid such collisions. We want each each wireless node to achieve a transmission rates that equals its arrival rate. One might want to implement a policy like MaxWeight or simply estimate the vector of arrival rates and accordingly choose the correct transmission rate. However, this is complicated by the fact that the routers do not know the arrival and transmission rates of their neighbors; all they can do is sense if their neighbors are transmitting or not.
We outline a clever and surprising result that shows that despite these limitations, there are algorithms that a stabilizing throughput is achievable for the maximum possible set of arrival rates. The model is as follows
- We consider a graph
, where
indexes a set of nodes and each edge
indicates that the nodes
and
cannot transmit simultaneously. Thus the set of admissible schedules is given by the set
\in{\mathcal E} \}.")
Note the schedules are the independent sets of the graph.
- As we saw with MaxWeight, the maximal region the node sizes can be stabilized for the set of arrival rates in the convex hull of
, which we denote by
.
Now, parameterized by 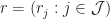
- With each node
we associate a rate
. If
and
, for all
the node will start to transmit.
- If
Notice the Markov chain above does not consider the queueing dynamics of the system, it is just interested in the states of the nodes, whether they are sending or not.
The following is a fairly straight-forward calculation for our Markov chain
Proposition: The stationary distribution, 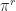
 =\frac{\exp\{ \sigma \cdot r \} }{ \sum_{\omega\in {\mathcal S}} \exp \{ \omega \cdot r\} }.")
for 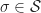
 := {\mathbb E}_{\pi^r}\left[ \sigma_j\right] = \sum_{\sigma\in {\mathcal S} } \sigma_j \pi^r(\sigma).")
The process is reversible and so above proposition is a straight-forward check of the detailed balance equations.
We now study the following function of 
 = \lambda \cdot r - \log \left( \sum_{\sigma\in {\mathcal S}} \exp\{ \sigma\cdot r \} \right).")
This intuition behind 



The function 
 := \sum_{\sigma\in{\mathcal S}} \nu_\sigma \log \left( \frac{\pi_\sigma^r}{\nu_\sigma}\right) = - \underbrace{\sum_\sigma \left( \nu_\sigma \sigma \cdot r \right)}_{=\lambda\cdot r} + \log \left( \sum_{\sigma\in {\mathcal S}} \exp\{ \sigma\cdot r \} \right) + \sum_\sigma \nu_\sigma \log \nu_\sigma = -F(r,\lambda) - H(\nu).")
Here 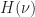
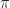
The relative entropy is minimized when
 \quad \text{over} \quad r\in{\mathbb R}^{{\mathcal J}}.")
The following proposition helps achieve this task:
Proposition: The function 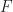
 = \lambda_i - s_i(r).")
Moreover 

 =\lambda_j,\qquad\qquad j\in{\mathcal J}.")
Proof: Notice that
.")
To confirm the strict concavity of

where 
![H_F= -{\mathbb E}_{\pi^r} [ ({\mathbf \sigma} - \mu)({\mathbf \sigma} - \mu)^{T} ]](https://s0.wp.com/latex.php?latex=H_F%3D+-%7B%5Cmathbb+E%7D_%7B%5Cpi%5Er%7D+%5B+%28%7B%5Cmathbf+%5Csigma%7D+-+%5Cmu%29%28%7B%5Cmathbf+%5Csigma%7D+-+%5Cmu%29%5E%7BT%7D+%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![\mu:= ({\mathbb E}_{\pi^r}[{\mathbf \sigma}_j] : j\in{\mathcal J} )](https://s0.wp.com/latex.php?latex=%5Cmu%3A%3D+%28%7B%5Cmathbb+E%7D_%7B%5Cpi%5Er%7D%5B%7B%5Cmathbf+%5Csigma%7D_j%5D+%3A+j%5Cin%7B%5Cmathcal+J%7D+%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![0= -\eta^T H_F \eta = {\mathbb E}_{\pi^r} [ \eta^{T} ({\mathbf \sigma} - \mu)({\mathbf \sigma} - \mu)^{T}\eta ]](https://s0.wp.com/latex.php?latex=0%3D+-%5Ceta%5ET+H_F+%5Ceta+%3D+%7B%5Cmathbb+E%7D_%7B%5Cpi%5Er%7D+%5B+%5Ceta%5E%7BT%7D+%28%7B%5Cmathbf+%5Csigma%7D+-+%5Cmu%29%28%7B%5Cmathbf+%5Csigma%7D+-+%5Cmu%29%5E%7BT%7D%5Ceta+%5D+&bg=ffffff&fg=1a1a1a&s=0&c=20201002)









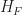
By differentiability if there is an optimum then it must satisfy the condition 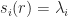
} = \frac{\exp\{ \lambda\cdot r \}}{\sum_{\sigma\in{\mathcal S}} e^{\sigma\cdot r}} \leq \frac{\exp\{\lambda\cdot r\} }{\exp\{ \max_{\sigma\in {\mathcal S}} \sigma\cdot r\}} \xrightarrow[||r||\rightarrow\infty]{} 0")
The above limit shows that the optimum must be achieved finitely, since solutions diverge away from zero. The limit to zero above holds (uniformly) as 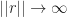
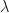
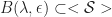
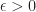


If we want to determine rates 
 = r_i(k) + \alpha \frac{\partial F}{\partial r_i} (r_i(k)) = r_i(k) + \alpha [\lambda_i - s_i(r(k))].")
The most most important observation is that the parameters 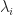
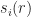


This gives the main idea of this line of work. However, there are many details required to deal with the recurssion . First, 
