- Dynamic Programs; Bellman’s Equation; An example.
For this section, consider the following dynamic programming formulation:
Time is discrete 



Def 1 [Plant Equation][DP:Plant] The state evolves according to functions 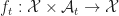
.")
This is called the Plant Equation.
A policy 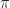
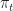





Def 2 [Dynamic Program] Given initial state 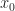

Further, let 

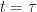

Ex 1 [Bellman’s Equation]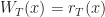

 = \sup_{a_t\in\mathcal{A}_t}\left\{ r_t(x_t,a_t) + W_{t+1} (x_{t+1}) \right\} ,")
where 

Ex 2 An investor has a fund: it has 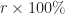
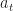
What should the investor do to maximize consumption?
Answers
Ans 1 Let 
 &= \sup_{{\bf a}_t} \left\{ R_t({\bf a}_t) \right\} = \sup_{a_t} \sup_{{\bf a}_{t+1}}\left\{ r_{t}(x_t,a_t) + R_{t+1}({\bf a}_t) \right\} \\ &= \sup_{a_t} \left\{ r_{t}(x_t,a_t) +\sup_{{\bf a}_{t+1}} R_{t+1}({\bf a}_t) \right\} =\sup_{a_t\in\mathcal{A}_t}\left\{ r_t(x_t,a_t) + W_{t+1} (x_{t+1}) \right\} . \end{aligned}")
Ans 2 The yearly fund value satisfies 



 \right\} \vee \left\{ 1+ \rho_{s-1} \right\}.")
Also, 

