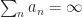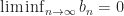We review the proof by Robbins and Munro for finding fixed points. Stochastic gradient descent, Q-learning and a bunch of other stochastic algorithms can be seen as variants of this basic algorithm. We review the basic ingredients of the original proof.
Often it is important to find a solution to the equation
")
by evaluating 

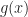
 + \epsilon_n")
and hope solve for 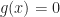
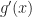

where we chose the sequence 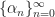

Before proceeding here are a few different use cases:
- Quartiles. We want to find
such that
for some fixed
. But we can only sample the random variable
.
- Regression. We preform regression
, but rather than estimate
we want to know where
.
- Optimization. We want to optimize a convex function
whose gradient is
for some large
. To find the optimum at
whose gradient,
, is an bias estimate of
Robbins-Munro Proof.
We now go through the main steps of Robbins and Munro’s proof. This proof is intentionally not the most general but instead gives the key ideas.
We assume that ![[x_{\min},x_{\max}]](https://s0.wp.com/latex.php?latex=%5Bx_%7B%5Cmin%7D%2Cx_%7B%5Cmax%7D%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![[y_{\min},y_{\max}]](https://s0.wp.com/latex.php?latex=%5By_%7B%5Cmin%7D%2Cy_%7B%5Cmax%7D%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
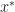


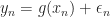
![\mathbb E [\epsilon_n] = 0](https://s0.wp.com/latex.php?latex=%5Cmathbb+E+%5B%5Cepsilon_n%5D+%3D+0+&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
In the steps below we prove the following:
Thrm [Robbins-Munro] If we chose 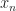
 ^2 ] \xrightarrow[]{n\rightarrow} 0")
where here
Ex 1. Let ![b_n = \mathbb E [ (x_n-x^*)^2]](https://s0.wp.com/latex.php?latex=b_n+%3D+%5Cmathbb+E+%5B+%28x_n-x%5E%2A%29%5E2%5D+&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

for terms

Ans 1.
^2 \\ &= \mathbb E ( x_{n+1} - x_n )^2 + 2\mathbb E [(x_{n+1} - x_n ) ( x_n - x^* )] + \mathbb E ( x_n - x^*)^2 \\ & = \alpha^2_n \mathbb E [ y_n^2] - 2 \alpha_n \mathbb E [g(x_n) ( x_n - x^* )] + \mathbb E ( x_n - x^*)^2 \\ & = a_n^2 e_n - 2 a_n d_n + b_n \end{aligned}")
as required.
Ex 2. Argue that 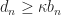
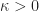
Ans 2. Since 
 - g(x^*)}{x- x^*} > \kappa , \qquad \text{for all } x\in [x_{\min},x_{\max}]\, .")
Thus
 ( g(x_n) - g(x^*) ) ] \geq \kappa \mathbb E [ ( x_n - x^* ) (x_n - x^* ) ] = \kappa b_n \, .")
Ex 3. Argue that if 
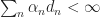

Ans 3. Summing the expression for [[RM:1]] over 
 = \sum_{n=0}^\infty (b_{n+1} - b_{n}) = \sum_n a^2_n e_n - 2\sum_n a_n d_n \, .")
Since 

Ex 4. Finally argue that if 
^2 ] \xrightarrow[n\rightarrow \infty]{} 0 \, .")
Ans 4. We know from [3] and [3] that

Since we choose